29.05.2023 - Змены ў праекце:
- абноўлены інтэрфейс пошуку (цяпер можна шукаць з варыянтамі напісання, знакамі прыпынку, пры дапамозе рэгулярных выразаў)
- дададзены тэксты 1920-1930х гадоў (~1,5 млн. слоў)
- дададзены дыялектныя тэксты (~500 тыс. слоў)
- часова прыбраны неразабраныя тэксты
Корпус тэкстаў сучаснай беларускай мовы са структурнай і граматычнай разметкай і пашпартызацыяй. Корпус складаецца з некалькіх падкорпусаў: асноўны, неразабраныя тэксты, газеты і сайты, Вікіпедыі (абодва правапісы). Аб'ём корпусу ~177 млн. словаўжыванняў, разам з неразабранымі тэкстамі ~1.07 млрд. словаўжыванняў.
Граматычная база ўяўляе сабой збор слоў з марфалагічнымі і іншымі паметамі. Вартасць граматычнай базы ў тым, што яна змяшчае не толькі словы, зафіксаваныя ў нарматыўных слоўніках, але і словы, якія з’явіліся ў беларускай мове за апошнія дзесяцігоддзі і ў слоўніках пакуль не адлюстраваны, што дазваляе назваць дадзеную базу базай актуальнай лексікі беларускай мовы.
Анлайнавы сэрвіс, які дапаможа вам пазбавіцца памылак у тэксце, напісаным па-беларуску афіцыйным правапісам. Таксама на старонцы сэрвісу вы зможаце спампаваць праграму праверкі арфаграфіі для розных браўзераў, Windows (уключна з Skype, Microsoft office і г.д.), LibreOffice/OpenOffice, Mozilla Firefox/Thunderbird.
Анлайнавы канвертар слоў і тэкстаў беларускай мовы у фанетычную транскрыпцыю з выкарыстаннем Міжнароднага фанетычнага алфавіта (IPA) і беларускай школьнай транскрыпцыі.
Сінтэз маўлення зроблены на падставе беларускага Mozilla Common Voice.
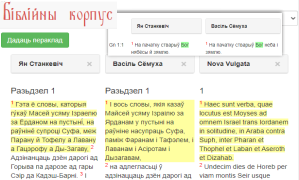
Беларускі Біблійны корпус змяшчае 16 перакладаў Бібліі на беларускую мову, а таксама тэксты на іншых мовах (лаціна, яўрэйская, украінская, польская і інш.) для параўнанняў і ўяўляе сабой зручны і эфектыўны інструмент для перакладчыкаў і даследчыкаў Бібліі. Пры дапамозе Біблійнага корпусу вы зможаце супаставіць тэксты перакладаў, а таксама знайсці патрэбнае слова і паглядзець варыянты яго перакладу ў розных выданнях.
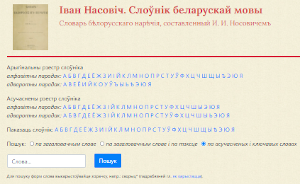
Электроннае перавыданне класічнай працы Івана Насовіча «Словарь белорусского наречия» (СПб., 1870) – галоўнай крыніцы слоўнікаў беларускай мовы канца ХІХ – першай паловы ХХ ст. Яно ўтрымлівае арыгінальны і асучаснены рэестр, арыгінальны тэкст і дадаткі; дапоўнена матэрыяламі крытычнага, біяграфічнага і бібліяграфічнага характару. Выданне забяспечана магчымасцю пошуку па тэксце і па ключавых словах, падабраных да аўтарскіх расейскамоўных дэфініцый. Адрасавана мовазнаўцам, гісторыкам, этнографам, фалькларыстам і ўсім, хто цікавіцца беларускім словам.

Лічбавы архіў, створаны на аснове Калекцыі фальклорных запісаў – найбуйнейшага і найстарэйшага фальклорнага архіва Беларусі. Тут прадстаўлены рукапісы (сканы-копіі экспедыцыйных дзённікаў і сшыткаў з тэкстамі песень, казак, замоў і інш.); фоназапісы (алічбаваныя гуказапісы беларускага фальклору); нотныя расшыфроўкі; сучасныя экспедыцыйныя фота-, гука- і відэаматэрыялы.
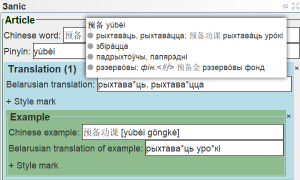
Праграма SloŭnikPlus створана з выкарыстаннем сучасных тэхналогій і істотна паляпшае працэс укладання слоўніка – значна павялічваецца эфектыўнасць, хуткасць і камфортнасць працы у параўнанні з больш звыклымі спосабамі (напрыклад, пры дапамозе MS Office). Дадатным бокам праграмы ёсць і тое, што яна працуе праз цэнтральны сервер, таму ўкладальнік не прывязаны да канкрэтнага камп’ютара і можа працаваць з любога месца пры наяўнасці інтэрнэт-падключэння.
Слоўнікі і іншыя праекты, якія створаны аўтаматычна з граматычнай базы.
https://daviedka.bnkorpus.info/ - Моўная даведка Інстытута мовазнаўства (НАН Беларусі)