本文梳理了斯拉夫国家语料库语言学发展中的白俄罗斯国家语料库的创建历史,并着重介绍了白俄罗斯国家语料库主库建设的三个主要方面:语言代表性问题及语料选取、语料库构建原则和文本要素标注、白俄罗斯语言词汇语法数据库的创建,最后介绍了主库外的生文本子库及特色软件的开发和使用。 The report reveals the history of the Belarusian N-korpus, the prototype of the National Corpus of the Belarusian Language, creation in the context of Slavic countries corpus linguistics. It describes the stages of its development: the national specificity of language representativeness determination, the Corpus building principles development, the Lexical and Grammatical Database of the Belarusian Language creation, specific software development.
很早之前,人们就意识人工整理手稿是一种低效的研究方式,借助计算机的辅助研究白俄罗斯语有着相当长的历史:在 20 世纪 70 年代末,在白俄罗斯科学院语言学研究所的马丁诺夫(Віктар Мартынаў)的领导下开始了语言研究自动化的工作,其方向之一是创建白俄罗斯语言的索引。目前也已创建了许多索引,如19世纪坎德拉特·克拉皮瓦(Kandrat Krapiva)作品索引、库兹马·科尔尼(Кузьма Чорны)作品索引(已丢失)。后来,这个方向的工作实际上被削减了,直到2010年才恢复(Сянкевiч 2017)。
而就语料库语言学发展来看,白俄罗斯曾有数个创建语料库的项目,其中重要的便是在“电子白俄罗斯(Электронная Беларусь)”国家计划框架内开发白俄罗斯语料库,其中包括“白俄罗斯语计算机基金(Mашынны фонд беларускай мовы)”信息系统(该计划于2005年结束)。此项目基础上已建成俄语-白俄罗斯语法律文本平行语料库,词库量达约100万 (Рубашко 2006)。
此外,作为该项目的一部分,2001年格罗德诺国立大学创建了扬卡·库帕拉(Янка Купала)经典文学文本语料库(Рычкова 1999)。
2001年,白俄罗斯国家科学院雅库布·科拉斯语言研究所批准了国家基础科学研究计划,计划的任务之一是确定“白俄罗斯语语言代表性和语料库建设原则问题”。这项任务由白俄罗斯国家雅库布·科拉斯(Якуб Колас)科学院语言学研究所斯拉夫语和理论语言系和明斯克国立师范大学弗朗西斯泽克·斯卡里纳(Францішак Скарына)科学教育中心科学术语系执行,根纳季·齐贡(Генадзь Цыхун)教授是该课题的负责人。在确定白俄罗斯语文本的代表性问题时,特别关注从文本功能的各个分支中选择最具代表性的文本,研究结果确定了以下内容:体裁代表性、历史时期代表性、地域代表性、拼写代表性。根据白俄罗斯语代表性的既定标准,选择了文本材料。此外,还开展了文本结构标注标准和原则的制定工作,解决了不少问题。
“白俄罗斯语代表性和语料库创建”主题的圆桌会议陆续举办,吸纳了一些感兴趣的机构和组织,如白俄罗斯国家科学院语言研究所、白俄罗斯国立大学、白俄罗斯弗朗齐斯卡·斯卡丽娜语言学会、格罗德诺国立大学。在圆桌会议上讨论了创建白俄罗斯语国家语料库的基本问题,并澄清了相关工作的一些分歧。
2005年第一个国家计划到期,新的2006-2010年国家计划开始。第二个国家五年计划中语料库的任务是“创建白俄罗斯语言文本语料库及其用于白俄罗斯语言研究”及语料库在研究与其他欧洲语言的关系方面的应用。这项任务是在明斯克国立语言大学信息学和应用语言学系主任亚历山大·祖博夫(Аляксандр Зубаў)教授的领导下进行,是前一个项目任务的延续,实际项目的开展地为白俄罗斯国家科学院语言学研究所,此举是为了保持项目工作的连续性(包括人员),充分利用前一阶段成果。在这个阶段,语法和结构标记体系已经制定出来,语料库语法基础部分工作也得以开展。最终项目阶段性成果包括100万词量的白俄罗斯单语语料库、一个英语-白俄罗斯语平行语料库以及30万词量的德语-白俄罗斯语平行语料库。只是在这一计划范围内创建的语料库是不公开的(Зубов 2006)。
与此同时,国际项目“波罗的海网格(BalticGrid)”启动。这一项目的目标是为波罗的海国家开发网格网络,建立可持续的电子基础设施,用于欧洲的各项科学研究,并加入泛欧电子基础设施网络。 2008年以来,在欧盟第七个计划框架内实施了国际项目“波罗的海网格二期(BalticGrid-II)”,为“波罗的海网格(BalticGrid)”项目的延续。“波罗的海网格二期”项目的目标是扩大和发展已有的基础设施,并将其转变为该地区及其他地区科学家的日常工作工具。同时,考虑到新加入的白俄罗斯纳米技术、机械工程等科学界的需求,该项目的全面实施为将“波罗的海网格”基础设施扩展到白俄罗斯提供了条件。
得益于“波罗的海网格二期”项目中为波罗的海国家和白俄罗斯开发语言资源方向,立陶宛(维尔纽斯大学)和白俄罗斯(白俄罗斯国立技术大学系统动力学和材料力学研究实验室和白俄罗斯国家科学院语言文学研究所的专家参与)开发了科学语言的文本语料库,分别是立陶宛语科学文本语料库和白俄罗斯语科学文本语料库。白俄罗斯语科学文本语料库 Corpus Albaruthenicum词用量达 35万(已删除同音异义词)(Кошчанка 2009)。
2011-2013年由白俄罗斯国家科学院语言文学研究所(现为白俄罗斯国家科学院白俄罗斯文化语言文学研究中心分院)、明斯克语言大学和维纳格诺多夫俄语学院组成的团队在白俄罗斯共和国基础研究基金的支持下实施了一个联合项目,创建平行的白俄罗斯语-俄罗斯语和俄语-白俄罗斯语语料库,其词量约为300万个(Сичинава 2012; Кошчанка 2013)。
建立一支国家团队至关重要,由此开展的前期工作解决了与单语国家语料库创建相关的许多理论和实践问题。同时,语言学研究所肩负着创建一本新的基础学术解释词典的艰巨任务。如果不创建一个大型语料库,这样一本词典的实施是不可能的,该语料库将包括各种风格和体裁的文本,并涵盖新白俄罗斯标准语的所有时期。
上述白俄罗斯语语料库研究并未达到国家语料库的整体水平。直到2015年,国家团队的实际创建工作才开始,2015-2016年的一个单独项目“创建白俄罗斯语国家语料库和词汇语法库及其软件支持”获得批准,该项目在白俄罗斯国家科学院雅库布·科拉斯语言学研究所进行。
在创建国家语料库方面,白俄罗斯落后于许多斯拉夫国家。到2015年,已创建国家语料库的有:克罗地亚(1998)、捷克(2000)、保加利亚(2001)、斯洛伐克(2002)、俄罗斯(2004)、波兰(2008)等。
在分析了已有的文本语料库创建标准后,如CES(语料库编码标准)、XCES(XML语料库编码标准)、ISLE(国际语言工程标准)、CDIF(语料库文档交换格式,BNC),白俄罗斯语国家语料库团队决定放弃某个特定标准,并创建一个基于XML并包含XCES元素的语料库。XCES标准旨在存储语料库,可为应用语言学、机器翻译、词典编纂等储备资源。
俄罗斯语国家语料库标准(стандарт Нацыянальнага корпуса беларускай мовы, СНКБМ) 区分了原始数据、(通常是为了非语言目的而创建)电子形式的“未注释”数据和语言注释(其中包含生成并附加到原始数据的信息)和一定的语言分析的结果。СНКБМ涵盖了与语言研究相关的主要数据对象的编码,例如:1)大部分话语,例如段落、章节等(以及标题、参考文献等);2)语言分析常用的段落元素,例如句子、通俗语言的引文、专有名称、日期、缩写、术语等。СНКБМ还涵盖文本和语音的语言注释的一致编码,包括形态句法注释、文本并行化等。
白俄罗斯国家语料库主库的后分区(元标记)仍然以相当有限的形式提供,但新版本的语料库正在准备中,用户将能够获得文本的完整描述。白俄罗斯国家语料库主库的元标记与其他斯拉夫语语料库略有不同,并且具有一组标准特征。实验语料的注释(标记)文本结构包括文本标题和原始数据编码。 每个语料库文档都有自己的标题,称为“文本标题”。 文本的标题由文档结构的描述(文件描述、标题的说明、版本和卷、来源的描述等)、编码的描述(文本中标签的声明、文本切分原理等),参数描述(文本来源、语言、字符布局等)。 因此,文本的标题包含其前文本的所有参数。
文本标题示例如下所示:
<标题>
(1) 书目描述
作品标题
*作者(或章节作者)*
出版地
文本数字化的版本
出版社
*出版年份*
*第一版年份*
创作年份
补充资料
(2) 文体描述
风格
类型
(3) 其他信息
*拼写注释*
附加说明代表性问题是任何语言语料库的首要问题。 正如道格拉斯·比伯(Douglas Biber)及其合著者指出的那样,“……重要的是要认识到,一种语言甚至语言部分的代表性是一项困难的任务。我们不知道语言的所有变异程度或全部的上下文变量,要捕捉到这些信息必须理清文本中的所有可变性。但是,对个别问题的关注可确保语料库尽可能具有代表性……”(Biber 1998: 246)。
白俄罗斯国家语料库创建的特殊性在于,必须在语料库内部解决实际语言代表性问题,从整体性出发的语言功能问题会影响语料库文本选择的有效性。白俄罗斯语的现状使解决代表性问题变得非常复杂。诸如白俄罗斯语几乎完全被排除在官方场景和许多科学分支之外、白俄罗斯语报纸的数量极少、白俄罗斯广播和电视播音员的文盲语言、存在几种带有子变体的拼写变体因素等等,使得文本的选择和代表性问题变得异常艰难。还应该指出的是,期刊文本的很大一部分实际上是俄语翻译,并且经常经过(良莠不齐的)编辑,甚至是未经编辑的机器翻译(例如,使用谷歌翻译)。在一些白俄罗斯语出版物中,俄语机器翻译的文本数量可能超过文本总数的90%。
这也是为什么2001年语料库的工作从语言代表性问题的研究开始。在确定白俄罗斯语文本的代表性问题时,特别关注从其功能的各个分支中选择最具代表性的文本的一般标准的定义。毫无疑问,代表性标准要求考虑文本中应出现的和语料库中应出现的所有可能的数据。2001-2005 年进行的研究结果确定了白俄罗斯语文本代表性的主要标准。应注意的是,随着时间的推移,这些标准发生了一些变化:
体裁代表性。最初确定文学文本应占语料库的30%左右,期刊约60%,专业文本约5%,口语文本约5%。我们优先考虑期刊,因为在期刊文本中可以更清楚地观察到语言发展的新趋势,而文学文本则保留了更多的保守主义,主要体现了二三十年前而非当下的语言特征。
此外,在“专业文本”子语料库中,定义了方向参数,这些方向参数反映了白俄罗斯语言在某些领域的功能范围。对书目数据的分析显示如下:语文学(文学研究、语言学等) — 33%,地理学和历史学(地理学、历史、地方志)— 24%,应用科学(医学、保健等)— 12%,数学和自然科学 — 9%,艺术 — 8%,哲学、宗教 — 6%,社会科学 — 5%,政治学、经济学 — 2%,文娱 — 1%。
如今,语料库的结构如下:期刊和新闻 — 58%,文学文本 — 8%,维基百科(2 个白俄罗斯语版本) — 27%,翻译文本 — 2%,其他文本(宗教、科学等) — 5 %。但值得注意的是,由于文本质量参差不齐(我们上面提到了机器翻译的问题),公众对期刊和维基百科文本的访问明显有限,而小说的份额则显着增加(高达 60-70%) 。
历时和历史代表性。语料库同时具有历时和共时的特征,包含了从16世纪的文本,尽管最初计划该语料库是共时的。白俄罗斯语的发展可分为以下历史时期: 1)古白俄罗斯语 (9-15世纪);2)16-18世纪; 3)新白俄罗斯语(19世纪);4)20世纪初 (1918年之前);5) 1918-1941年; 6) 1941-1945年(伟大的卫国战争);7)1945 - 1991年;8)1991至今。
如今,语料库涵盖了除11世纪至15世纪、20世纪初(1918 年之前)和1941-1945 年(伟大的卫国战争)之外的大部分时期。目前,16至18世纪的文本(主要是白俄罗斯先锋印刷商弗朗西斯科·斯科里纳的出版物)和1918-1941年的文本仍然很少。1918年至1941年这一时期对于白俄罗斯新标准语的发展极其重要。1918年,布拉尼斯拉夫·塔拉什基耶维奇(Браніслаў Тарашкевіч)在维尔纽斯出版了第一本《白俄罗斯语中小学语法》,这是创建白俄罗斯语规范语法的首次尝试,并成为20年代拼写规范的起点。 1918-1919年,现代第一部翻译词典问世。与此同时,创建了参与白俄罗斯语言发展的科学机构:白俄罗斯科学协会(1918 年1月,维尔纽斯)、教科书编译和翻译局(1918年,明斯克)、明斯克白俄罗斯教育学院研究所(1918年12月)、科学术语委员会(1921年2月)、白俄罗斯国立大学(1921年10月)、白俄罗斯文化研究所(1922年1月),1929年改组为白俄罗斯科学院(1929年)。白俄罗斯文学语言正常化问题已达到国家层面。
这一时期的特殊意义在于它不仅是民族文学经典著作的创作和出版时期、图书印刷的繁荣时期、民族语言学奠定基础的时期,也是现代语言规范形成的时期,决定了我们的工作重点。创建白俄罗斯书面文本语料库:在国家科学院语言研究所2021-2025年国家研究计划“白俄罗斯国家社会与人道主义安全”第6号子计划“白俄罗斯语言和文学”框架内白俄罗斯科学院已开始创建“1918-1941年白俄罗斯语文本电子语料库”。
地域代表性。由于主要出版中心集中在明斯克,因此大部分语料库材料由在明斯克出版的文本组成,其余为在其他区域中心和国外出版的文献。
拼写方式的代表性。这也是创建白俄罗斯语语料库是一个相当复杂的方面,因为至少有两个拼写变体(官方版和“塔拉什克维茨(тарашкевіца)版本”),并且它们之间的变体数量不定。理想情况下,语料库应包含两种拼写方式的文本。迄今为止,由于各种原因(执行者数量少、缺乏资金等),有些建议无法实施。 例如,一些研究人员指出,语料库中“塔拉什克维茨”文本很少(Peljak-Łapińska 2016:208)。这是因为词汇语法基础尚不支持规范拼写之外的拼写,因此不可能通过单词及其所有单词形式进行搜索。因此,包含不规范拼写的文本会带来一定的不平衡,给语料库的使用带来不便。
因此,白俄罗斯国家语料库是一个通用语料库,未来计划在此基础上创建平衡语料库。 我们可以在波兰国家语料库和捷克国家语料库中看到类似的方法,其中存在完全不平衡的大型语料库和小得多的平衡语料库。为了解决这个问题,我们必须补充一个事实,即由于文本数量有限,建议在语料库中额外包含一些翻译文本,这通常不推荐,但在文本选择存在的语言中实践是可行的。
平衡问题是许多斯拉夫语料库的特征。的确,在捷克国家语料库的框架内,曾多次尝试打造一支平衡语料库团队,但不能说其中任何一个团队都能完成所有任务。在编写“具有社会意义的特殊词汇词典” 时(Станкевич 2017),也出现了类似的情况,结果证明它并不代表价值数百万美元的报纸文本子语料库,而是格罗德诺地区媒体语料库中白俄罗斯语的一小部分。
在白俄罗斯国家语料库主库中,计划首先通过扩展为用户插入自己的子语料库的可能性来解决所描述的问题,这可以部分消除代表性问题。
原始数据的编码包括文本结构元素的选择,分为三个层次:文本层次、段落层次和子段落层次。文本级编码涵盖文本内容、章节、章节和段落的表示法。引文标题、对话段落、诗行都标记在段落内。如有必要,还可以标记表格和图形。 在第一阶段,我们确定了以下要素:
| 元素 | 属性 | 描述 | ||
|---|---|---|
| body | (文本内容)— 包含全部文本 | |
| div | 文档部分(如章节) | |
| type | 指定文档部分的类型(部、章、节等) | |
| head | 标题 | |
| p | 段落 | |
| s | 句子 | |
| w | 要素(词、短语、标点符号) | |
| lemma | 词素(初始形态) | |
| cat | 语法信息 | |
分段级编码包括句子、单词、标点符号、缩写、列表、日期、数字、专有名称、术语、外来词、引号中的对话的标记,必要时可以使用校对记忆。为了突出显示上述结构元素,创建了标记化规则(将文本拆分为单词):
本库也已经开发了用于自动文本分割和标记化的软件工具。白俄罗斯语国家语料库的文本准备程序是在免费的语料库语言学软件项目的基础上制作的,该项目在 GPLv3 许可证下分发。
该程序目前支持以下功能:1)将纯文本文件转换为语料库格式;2)将文本分割成单独的段落和句子;3)根据定义的规则对句子进行标记;4)* 根据词汇语法基础自动确定引理和语法描述;5)* 语义标记。
要处理程序中的文本,必须按如下方式准备:1)扩展名为 .txt 的普通文本文件,其中一行包含一个段落;2)文件的字符集必须是UTF-8。选择这个字符是因为它包含了所有语言的字母(因此不会出现文本中外文引用的问题),并且是Unicode中最常见的字符集;3)一些文本标签,例如作者、标题、出版年份可能会在文本开头给出。在这种情况下,它们将出现在语料库的结果文件中。
将文本分割成单独的段落非常简单且明确,因为原始文本文件应采用“一行 - 一个段落”的格式。而句子分割和标注是一个更困难的问题,因为它们根据某些规则工作,而这些规则并不总是给出明确的结果。例如,并不总是能够自动确定句号是句子边界还是缩写。 文本中也存在印刷错误。自动分段和标记化会产生约2%的错误,这些错误只能在手动审核期间纠正。
此程序在用户的计算机上运行,仅使用从词汇语法数据库中读取的内容。不同的人可以同时使用该程序(每个人都在自己的计算机上),但每个人都会处理自己的文本。这个过程类似于在文本编辑器中编辑纯文本:1)将打开一个文本文件;2)该程序进行自动分段和标记化;3)专家编辑文本、更改分段、标记化、删除同音异义词等;4)文本以语料库格式存储并传输到语料库文本存储库。
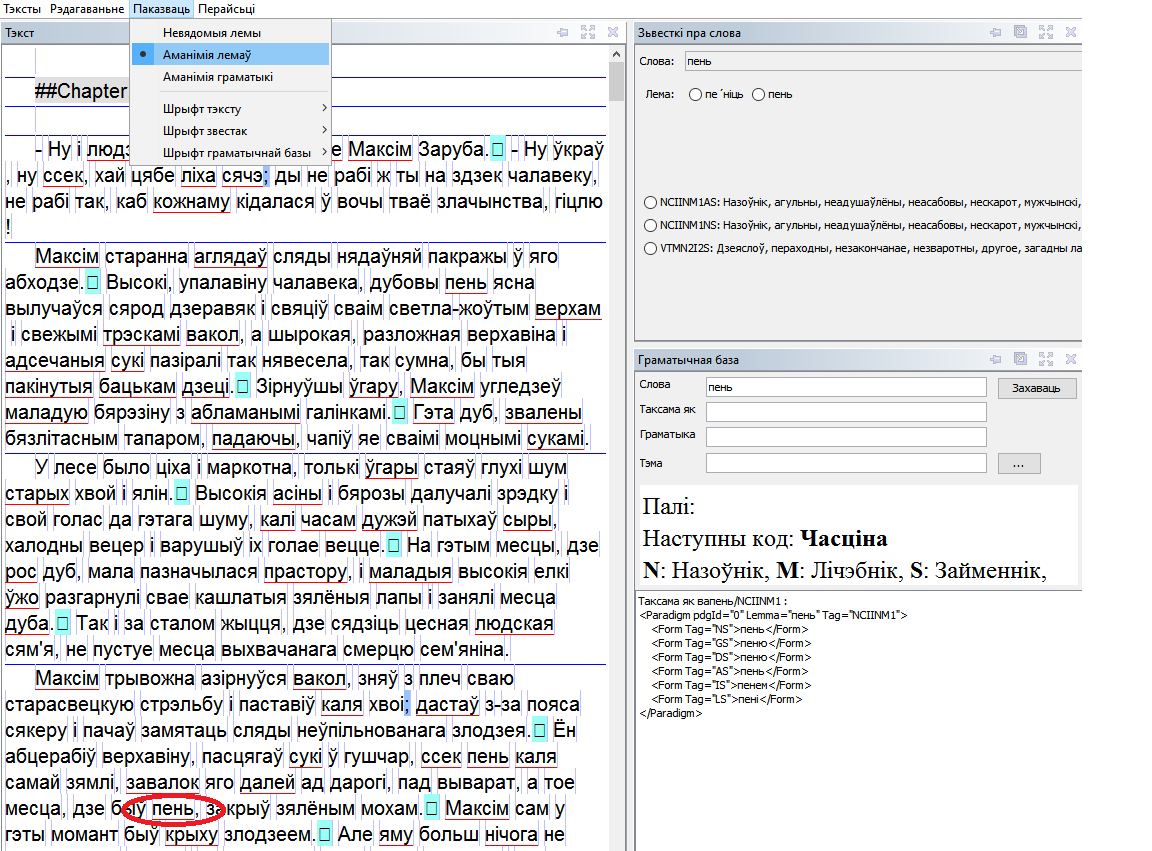
该程序允许用户在多种模式下工作: 1) 未知引文:未包含在词汇和语法数据库中的单词会突出显示。该程序允许用户扩展所选词的范例,分配适当的语法并将单词添加到数据库中; 2) 引文的同义性:部分同义的单词会突出显示(参见上图中的示例)。该模式允许用户以半自动模式删除部分同音词;3)语法同名:具有语法同名(一种范式内的同名)的单词被突出显示,语法同名去除也是半自动进行的。
此外,程序还显示了段落、句子和单词的边界,使用户可以在初步自动评估时控制结构元素指定的正确性。保存时,程序将处理后的文本转换为语料库格式:
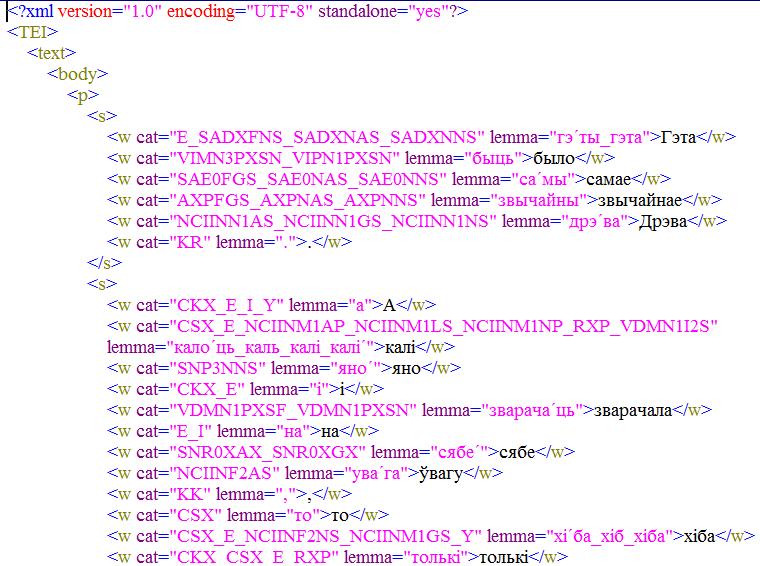
像大多数斯拉夫语语料库一样,白俄罗斯国家语料库主库还编码形态(语法)信息:词的初始形式和语法特征。对于语料库的语法标记,使用词汇语法基础,该基础根据Creative Commons Attribution/Share-Alike 3.0许可证的条款进行分发。目前,词汇语法数据库拥有大约 26.5万个范例和超过 250万个词形。
语法基础库是具有形态和其他形式词汇集合。范式标识号(pdgId)、初始形式(Lemma)、词格的语法符号(Tag)在范式标头中提供。如有必要,还记录附加信息:对动词的变位(Govern)、含义(Meaning)注释。每种屈折形式都有自己的特点(Form Tag)。还标注出词或词形式的来源、重音、拼写、非规范形式。词汇语法库的价值在于,它不仅包含规范词典中记录的单词,还包含近几十年来白俄罗斯语中出现的单词(以1990年以后创建的文本为基础),并且收录了词典中尚未出现过的单词。显然,这使我们可以将该数据库称为白俄罗斯语现代词汇数据库。词汇语法数据库中的范式具有以下形式:
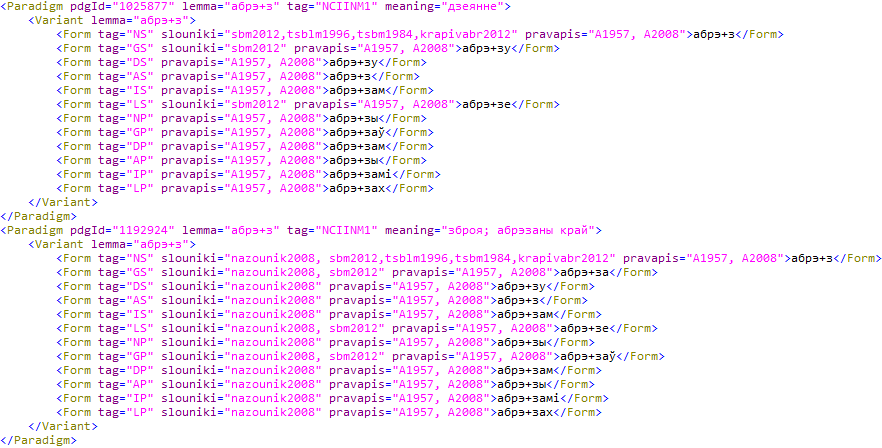
这一程序可以在任何支持 XML 语法的文本编辑器中进行编辑。在“创建白俄罗斯语国家语料库和词汇语法基础及其软件支持”项目实施过程中,改进了语法记忆系统,确定了部分语言的词汇语法特征(分析该语料库使得对语法中以两种方式解释的事实进行明确、无矛盾的评估成为可能)(Маракулiна 2016; Лапценак 2015)。
白俄罗斯国家语料库还设计开发了一系列独立软件,本文重点介绍:编辑器、编译器和检索器。
对文本的准确、全面的描述应该无一例外地涵盖和适合语料库中包含的所有文本(它们在风格、类型、体裁等方面有很大差异),即要统一。因此,语料库中包含的每一篇文本都需要经过“护照化”——也就是说,为其提供最完整的书目描述。文本“护照”的主要特性是信息丰富和调取迅速,可在短时间内提供了文本最完整的情况,这在当今尤为重要。
通过对语料库文本填写“护照”的各种方案和原则进行研究和分析,并考虑到文本功能的民族语特殊性,制定了以下“护照”处理基本原则,其中定义为最重要的包括:(1)作者(一位或多位作者;匿名作品和作者身份有争议或无法证明的作品的问题也在此列);(2)名称/标题(显示标题更改或缺失的情况,特别是在短诗歌形式的作品中);(3)文本数字化的版本;(4)地点、出版年份、出版社/来源(十月革命前或战前印刷的文本中可能会缺少一个要素);(5)风格、体裁(定义体裁和语体分类的不同方法);(6)创建年份(日期可延长:1989年8月1日 - 1990年5月26日;延长时间:1954年3月15日 - 1957年10月8日、1962年1月 - 1967年9月12日,*尤其适用于亲笔签名和打字稿,如果它们还幸存的话);(7)出版年份;(8)首次出版年份;(9)简短的附加说明(重印时首次出版的地点和日期、编辑、插图的可用性、页数、参考书目)。
此外,还开发了一个程序,允许您以半自动模式创建文本护照。例如,以下信息被添加到文件中:
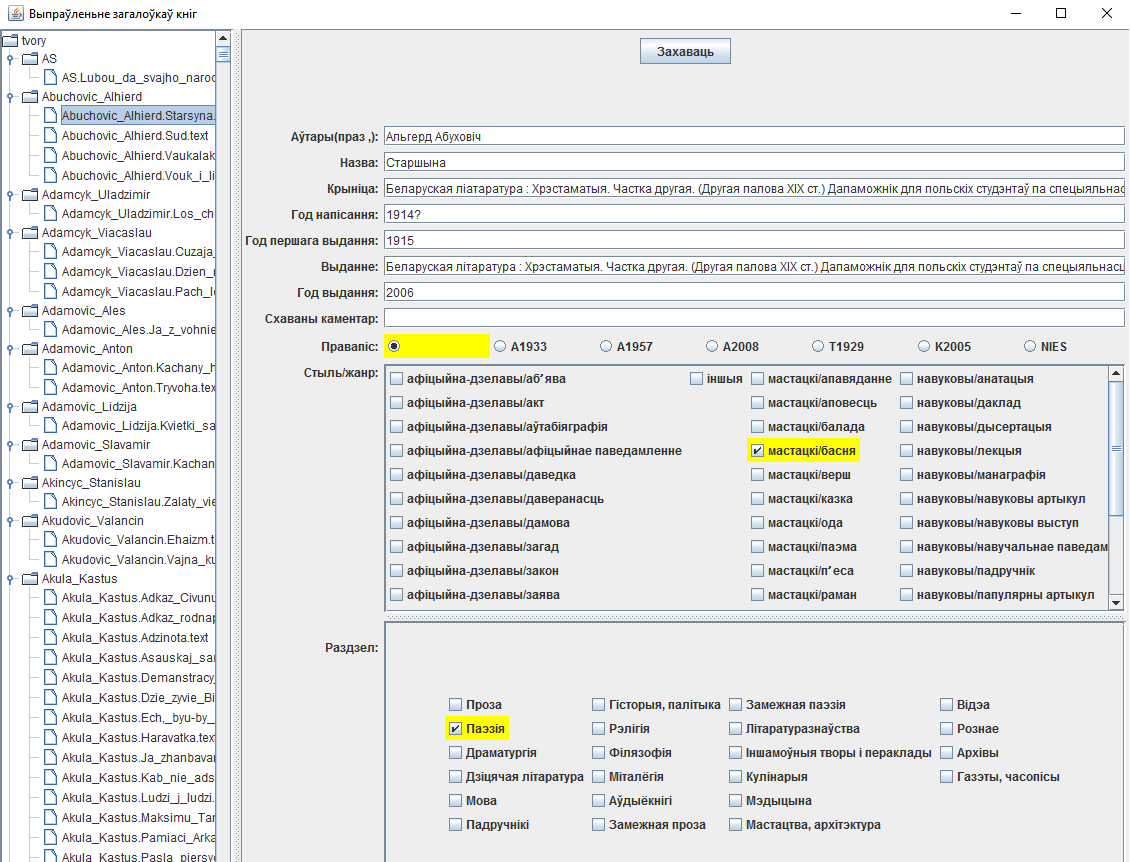
##作者:阿尔格德·阿布霍维奇
##头衔:主席
##主题:诗歌
##描述:首次在白俄罗斯日历“我们的领域”中发布 1915 年 - 维尔纽斯,1915 年
##版本:白俄罗斯文学:参考书目。 第二部分。 (十九世纪下半叶)波兰“白俄罗斯语言学”专业学生手册/投稿。发表评论。 M·豪斯托维奇。 锰,2006 年。- 204 页
##体裁类型:小说/寓言
##创作年份:1914
##出版年份:2006
##首次出版年份:1915
##文本类型、流派和风格其中“文本类型、流派和风格”选项定义和细化了文本准确描述的一些参数的理论基础,特别是定义了文本类型、体裁和风格以及文本格式的“护照”参数。文本体裁的概念是一种典型的可再现的表达形式,其特点是主题内容、构成和风格的统一,由巴赫金(Михаил Бахтин)提出,被认为是文体学、文本语言学、社会语言学的基本思想。每个语言领域都发展了自己的语言体裁库:在学科领域,具体体裁可分为科学文章、专著、教科书、文摘等,在新闻领域,具体体裁可分为笔记、报告、采访等,在商业领域,具体体裁包括公务领域(法律、条例、法令等)和文艺领域(小说、短篇故事、故事等)。
然而,术语“体裁”的主要缺点是它的模糊性。除了对该术语的语言理解之外,还有定义和描述小说类型的文学传统。因此,为了避免术语混淆和混乱,决定使用语料库数据库中的中性词“文本类型”来描述文本的体裁形式(俄罗斯国家语料库中也使用该参数)。因此,“文本类型”参数确定该文本是否属于某种语言体裁。目前,该参数的值为约100项的列表。 在此列出“文本类型”的一些示例,如:概述、公告、短篇小说、短篇小说、文章、联想散文、自传、上诉、占星、手册、合同、日记、法律、声明、访谈、说明、童话、评论、私人信件、商业信函、祈祷、专着、回忆录、缩略图、素描、笔记、教科书、戏剧、小说、摘要、评论、报告、专题、编年史、散文等。
决定保留“体裁”参数,仅在描述文学文本时使用它。从这个意义上来说,它被理解为一种文学类型的个性化表现,这是由作品的主题决定的:自传体散文、历史散文、幽默讽刺、儿童文学、侦探故事、爱情故事、神话、非体裁散文(用来表征主流“严肃”小说)、冒险、科幻奇幻等。
“风格”选项中的术语“风格”并没有因为这种模糊性和不同的定义方法而被区分,因此,为了方便语料库的用户,决定使用该术语的传统含义,即被理解为已经发展起来的语言手段系统。从历史上看,它被用于人际关系的一个或另一个领域,并在交流中发挥一定的功能。在每种风格中,一些研究人员区分了几种子风格。但为了避免特性混淆以及术语定义和填写的混乱,以及为了便于使用,在标记中标明了以下样式:科学、新闻报道、公务、会话、艺术、宗教。我们还认为引入一个注释来描述文本的词汇构成并反映其文体特征是适当的:中性(反映风格规范)、官方的、专业的、地区性(方言)、少数的、自创。
编译器是一个Java程序,仅供语料库管理员用来准备新版本的数据。它包含所有语法标签,读取语法基本信息,读取所有带或不带删除同音异义词的文本。对于每个单词,定义一个语法标签和一个引文,将文本分成单独的段落(然后以随机顺序混合,这样就不可能恢复原始文本以解决版权问题),结果将存储在搜索界面所使用的数据库中。
编译器的数据基础使用Apache Lucene数据基础。与常规SQL数据基础(PostgreSQL、Oracle、MariaDB等)不同,Apache Lucene数据基础更适合存储所有对象(因为段落中的单词数可能不同,并且每个单词可能具有不定数量属性的信息),可以考虑不同数量的语法记忆和“只读(不编辑)”场景。
白俄罗斯国家语料库主库(约 12.2 亿词量)在 i7-4770 处理器上编译约需1小时。
搜索器中搜索接口的要求不同,即它必须可以通过互联网访问。因此检索器被制作为具有Angular+Bootstrap 接口的 Java Web 应用程序,并使用编译器生成的语法标签、语法基本信息和语料库文本基本信息。
用户的查询可能比简单的单词搜索复杂得多(即使单词发生变化)。因此,使用“双通道”搜索,即通过单词和语法标签在数据库中搜索段落,然后额外检查找到的段落是否符合更复杂的搜索条件,确认这些条件是否满足处理需求。
使用 Apache Lucene 而不是 SQL 的另一个好处在于它是一个 Java 库,并且与搜索界面在同一进程中运行。这使得无需将数据从SQL Server传输到搜索界面,从而显著加快搜索速度。Hull引擎根据GPLv3免费许可证分发,可适用于任何语言的搜索。
目前,白俄罗斯国家语料库已创建了一个包含约12.2亿词量的主库,并标注词汇的结构和语法,将部分文本“护照化”,开发了语料库检索引擎,词汇语法数据库也进行了扩充和精炼,如今的词量约为26.5万。总库包括以下9个部分:主语料库、弗朗西斯科·斯科里纳出版物语料库、19世纪白俄罗斯语词汇索引、网络资源语料库、白俄罗斯维基百科语料库、翻译语料库、方言语料库、生文本库、圣经语料库。
主语料库包含阅读的文本,其中有元标记:文本作者、文本标题等。主语料库允许用户搜索单词的确切形式、单词所具有的各种形态、根据单词的语法特征搜索单词。用户也可以按作者、写作年份、风格、体裁等进行搜索。已经创建了按簇/词组(相邻单词的组合)采样的可能性。19世纪白俄罗斯语词汇索引包括“19世纪白俄罗斯语标准”出版物文本。网络资源语料库包括白俄罗斯语报纸、杂志和其他重要在线资源的电子版文本。白俄罗斯维基百科语料库的文本来自两个白俄罗斯语维基百科的文本(它们之间的区别在于使用不同的拼写系统)。翻译语料库主要收录的是文学作品的翻译文本。方言语料库包含来自白俄罗斯不同地区和邻近领土的白俄罗斯语方言文本。生文本库是已自动识别但未经校对的文本集合(存在词汇粘黏、分句、段落等问题)。生文本库允许用户搜索单词和单词形式,但没有成熟的元标记。圣经语料库包含 16 个白俄罗斯语圣经译本,以及其他语言(拉丁语、希伯来语、乌克兰语、波兰语等)的文本以供比较。借助圣经语料库,用户可以比较翻译文本,找到正确的单词并查看其在不同版本中的翻译方案。
为了满足国内外翻译的实际需要(白俄罗斯有两种官方语言:白俄罗斯语和俄语,欧亚经济委员会的文件正在积极翻译成白俄罗斯语),建立俄语-白俄罗斯语平行语料库的工作已经开始。
白俄罗斯国家语料库是保护和发展白俄罗斯语的多项举措之一,它不仅为白俄罗斯语言学、文学、教育、翻译等领域提供数据和资源,支持各种基于语料库的理论和应用研究,也为白俄罗斯与其他国家和地区进行文化交流和合作提供一个重要平台。当然,白俄罗斯国家语料库也面临的一些挑战,如扩大规模和覆盖范围,增加口语、网络、多媒体等类型的文本,提高白语料库的质量和可靠性,完善文本的编码和标注,优化搜索和分析工具,增强影响力和知名度,吸引用户和合作伙伴,参与国际项目和活动等。白俄罗斯是中国在欧亚地区的重要合作伙伴,也是共建“一 带一路”倡议的积极参与者和支持者,但目前国内对于白俄罗斯国家语料库的关注较少,希望本文可以引起国内同仁的兴趣,进一步探索白俄罗斯国家语料库在理论和应用方面的潜力价值,促进两国间语料库的合作与交流。
Biber D., Conrad S., Reppen R. Corpus Linguistics. Investigating Language Structure and Use[M]. Cambridge, 1998.
Зубов А.В., Кощенко В.А. Корпус текстов белорусского языка[C]//Труды международной конференции «Корпусная лингвистика – 2006», Санкт-Петербург, 2006: 119-120.
Резникова Т.И. Славянская корпусная лингвистика: современное состояние ресурсов[C]//Национальный корпус русского языка: 2006—2008. Новые результаты и перспективы. СПб.: Нестор-История, 2009: 402-461.
Рубашко Н.К. Компьютерный фонд белорусского языка и его приложения[C]//Информационные системы и технологии (IST’2006): материалы III Междунар. конф., Минск, 2006: 71-70.
Сичинава, Д.В. Русско-белорусский параллельный корпус: опыт разработки[C]// Карповские научные чтения, Минск: «Белорусский Дом печати», 2012: 270-272.
Станкевич А.Ю. Система ссылок на источники в корпусе контекстов для словаря социально значимой специальной лексики[C]//Современные проблемы лексикографии, Минск: Четыре четверти, 2017: 88-92.
Bańko Mirosław, Rafał L. Górski. Praktyczny przewodnik po korpusie języka polskiego[C]//Praktyczny przewodnik po korpusach języków słowiańskich, Warszawa: Wydział Polonistyki Uniwersytetu Warszawskiego, 2014: 11-28.
Kopřivová M., WaclawičováM. Representativeness of Spoken Corpora on the Example of the New Spoken Corpora of the Czech Language[C]//Proceedings of the international conference Corpus linguistics, St. Petersburg: St.-Petersburg University Press, 2006: 174-181.
Peljak-Łapińska A. Białoruski N-korpus: w kierunku Białoruskiego Korpusu Narodowego[J]//Acta Albaruthenica, 2016 (16): 203-210.
Milena Hebal-Jezierska. Praktyczny przewodnik po korpusach języków słowiańskich[M]. Warszawa: Wydział Polonistyki Uniwersytetu Warszawskiego, 2014.
Кошчанка У., Капылоў І., Міклашэвіч І. Корпус беларускамоўных навуковых тэкстаў як частка рэалізацыі міжнароднага праекта “Balticgrid II” [J]//Беларуская лінгвістыка, 2009(53): 3–8.
Кошчанка У. Паралельныя беларуска-рускі і руска-беларускі корпусы на сайце нацыянальнага корпусу рускай мовы[C]//Проблемы современной прикладной лингвистики, Минск: МГЛУ, 2013: 41-47.
Рычкова Л.В. Камп’ютэрная версія драматургічпых твораў Янкі Купалы: прыпцыпы стварэння, напрамкі выкарыстання[C]//Міжнародныя купалаўскія чытанні: матэрыялы навуковай канферэнцыі. Гродна, 1997.
Сянкевіч Н.М. Канкарданс як сродак выяўлення асаблівасцей мовы мастацкай літаратуры[C]// Актуальные проблемы современной прикладной лингвистики, Минск: МГЛУ, 2017: 248–254.